Indices
OpenSearch® uses indices to organize data into types, similarly to databases and tables in relational databases.
The data is distributed within your cluster by mapping each index to a primary shard, which is copied to one or more replica shards to protect your data against hardware failure and to provide additional capacity for read requests.
Aiven for OpenSearch does not place additional restrictions on the number of indices or shards that you can use for your service, but OpenSearch does have a default limit of 1024 shards.
Choosing when to create new indices
As the number of indices affects the performance of your service, it's good to consider your strategy for creating new indices.
Consider creating a new index for each customer, project, or entity if you have a limited number of entities (tens, not hundreds or thousands). It is also important that you can easily and efficiently delete all the data related to a single entity.
For example, storing logs or other events to date-specific indices
(logs_2018-07-20, logs_2018-07-21, etc.) adds value as long as old
indices are cleaned up. If you have low-volume logging and you want to
keep indices for longer times (years rather than weeks), consider using
weekly or monthly indices instead.
Avoid creating a new index for each customer, project, or entity if:
- you have a very large number (thousands) of entities, or
- you have hundreds of entities and need multiple different indices for each one, or
- you expect a significant increase in the number of entities, or
- you have no other reason than to separate different entities from each other.
Instead of creating something like items_project_a, consider using a
single items index with a field for your project identifier and query
the data with OpenSearch filtering. This is a far more efficient way to
use your OpenSearch service.
Setting the number and size of shards
The number of shards that you need depends heavily on the amount of data that you have. Regarding the size allocation, a general recommendation is to use somewhere between a few gigabytes and a few tens of gigabytes per shard:
- If you know that you will have only a small amount of data but many indices, start with 1 shard and split the index if necessary.
- If you have tens of gigabytes of data, start with 5 shards per index to avoid splitting the index for a long time.
- If you have hundreds of gigabytes of data, divide the amount of data in gigabytes by ten to estimate the number of shards. For example, use 25 shards for a 250GB index.
- If you have terabytes of data, increase the shard size further. For example, for a 1TB index, 50 shards would be a good starting point.
These are only rough suggestions; the optimal values depend heavily on how you use your data and the growth forecast for your OpenSearch data. You can change the number of shards without losing your data, but this does cause some downtime when rewriting the index.
Performance impact
Having a large number of indices or shards affects the performance of your OpenSearch service. For OpenSearch clusters, Aiven allocates 50% of the available memory to the JVM heap; the remaining 50% is reserved for the underlying OS and caching in-memory data structures. 20 shards, or fewer, per GB of heap memory, should be set as per shard count recommendation.
As an example, an OpenSearch business-8 cluster comes with 8GB RAM. 20 x (8 x .5) = 80, or less, would be the recommended configuration for the number of shards.
The size of the shard impacts the recovery time after a failure. Shard sizes between 10GB to 50GB should be set as per shard size recommendation.
Aiven for OpenSearch takes a snapshot once every hour. With shards exceeding recommended configuration, the cluster continuously takes new backups and deletes old backups from storage. This naturally affects the service performance, as part of the capacity is constantly allocated to managing backups.
OpenSearch plan calculator
To help calculate a good shard configuration to use, we've shared our plan calculator. This OpenSearch plan calculator can be used online or downloaded:
- View on Google Docs - Make a copy to your Google drive to use it.
- Download XLSX - Download and use it locally.
By adding the values you know about the nodes and RAM in your setup, you can get some recommended starter values to use for your setup.
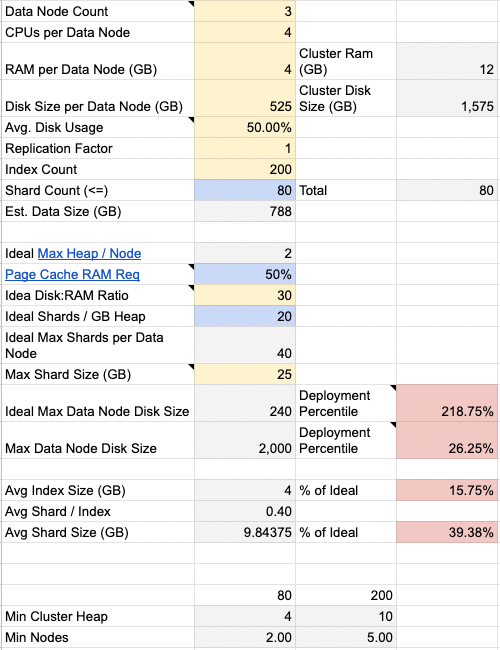
Yellow cells such as data node count, CPUs, RAM, Max Shard Size
and etc. are input values to calculate recommendation values for plan
sizing.
The Dashboards from Aiven for OpenSearch are not compatible across minor versions. Because of this, if existing current nodes of your service instance are of an older version, you can expect a downtime during migration or plan changes.
Using patterns to set index retention
The standard index retention approach is setting the maximum number of indices to store. On exceeding that number, the oldest index is deleted. However, this has some limitations. For example, you might want to set the maximum to 5 for one type of index and 8 for another type.
Aiven for OpenSearch services gives you the option to create glob-style patterns and set a unique maximum for each pattern.
Here are some examples of the patterns that you can use:
logs: matcheslogsbut notlogsfooorfoologslogs*: matcheslogsfooandlogs_foo_barbut notfoologs*_logs_*: matchesfoo_logs_barbut notfoologsbarlogs.?: matcheslogs.1but notlogs.11
You can also use * as a catch-all pattern that matches all indices.
However, this iterates through all your patterns, so you should consider
the impact carefully before using it.
For example, if you have log indices logs.1, logs.2, and so on, up
to logs.34, along with new test.1, test.2, and test.3 indices
that are intended for testing purposes but are not in use yet.
If you create a logs.* pattern with the maximum set to 8 and a *
pattern with the maximum set to 3, the system iterates through your
patterns one by one. First, it makes sure that it only keeps the 8
newest log indices based on your logs.* pattern. Then, it runs the *
pattern, which affects all your indices, and since the test indices are
the newest ones, it keeps those and deletes all your log indices. Keep
this in mind, and be careful when setting a catch-all pattern.
Additionally, setting the maximum to 0 means that your pattern has no effect. The system ignores the maximum setting and does not delete anything. You can use this if you want to disable the pattern temporarily.
If you use log integration with integration-specific retention times, note that Aiven for OpenSearch applies both index patterns and integration retention times. If you use both log integrations and custom index patterns in your OpenSearch service, we recommend that you use only one of them to clean up indices:
- Set the retention time for log integrations to the maximum value (10000)
- Do not add index patterns for index prefixes managed by log integrations
You can set both, in which case the smaller setting takes effect.
Automatic adjustment of replication factors
Aiven for OpenSearch automatically adjusts the index replication factor (the number of replica shards) to ensure data availability and service functionality.
The replication factor is adjusted automatically:
- If
number_of_replicasis too large for the current cluster size, it is automatically lowered to the maximum possible value (the number of nodes on the cluster - 1). - If
number_of_replicasis 0 on a multi-node cluster, it is automatically increased to 1. - If
number_of_replicasis between 1 and the maximum value, it is not adjusted.
When the replication factor (number_of_replicas value) is greater than
the size of the cluster, number_of_replicas is automatically lowered,
as it is not possible to replicate index shards to more nodes than there
are on the cluster.
The replication factor is number_of_replicas + 1. For example, for a
three-node cluster, the maximum number_of_replicas value is 2, which
means that all shards on the index are replicated to all three nodes.
Elasticsearch is a trademark of Elasticsearch B.V., registered in the U.S. and in other countries.